

Introduction to Machine Learning
Hello there…
Welcome to machine learning magazine. Here you will learn how machine learning is used in several key fields and industries in the world today. Fields such as; manufacturing industries, pharmaceuticals and medical organisations, streaming services such as Netflix, Hulu etc, robotics companies, financial organisations, environmental organisations and so much more. Before I go any further, kindly note that this introduction page is brief, just to give you a sneak peak of what machine learning is about before diving hands-on into use case examples in other posts of this magazine. If you are new to data science, please go through this page before continuing to other posts. Although this magazine is project based, here are some materials that could help you understand methods used whilst giving you an in-depth study in the process. Hands-on Machine Learning with Scikit-Learn, Keras and TensorFlow by Aurélien Géron for which many of the principles of this magazine is generated. Also read NLP with python by Steven Bird & co. This is old but a rare gem. For data wrangling and manipulation, look no further than Python for Data Analysis by Wes Mckinney.
Now, What is Machine Learning?
Simply put,
“Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed” (Arthur Samuel, 1959).
Let me explain what this means. Suppose you have a dataset that represents a number of breast cancer patients say 100,000. You are then asked to check if the diagnosed breast lump is either benign or malignant using traditional programming methods. You would start by looking at the characteristics of a malignant tumor such as its clump variation in size and shape, its mitotic count, the abnormality of cell chromosomes and DNA etc. Next, you would want to write an algorithm that would identify each of the above patterns and further label a cell accordingly. As a programmer, am sure you can envision a long list of complex rules that would ensue from a set of IF, THEN, ELSE rules just to show its clump size and shape. This method is mostly bound for failure because these rules however complex and cumbersome, are highly dependent on your current data. Suppose you have new patients (out of sample cases) that you want to do a diagnosis on? Yes… you got that right. You would also be needing new set of rules for them. What this invariably means is, every time you get new samples, you would have to write new algorithms since finding a pattern is not manually feasible, making the whole process computationally expensive. What if we could find some way to train our existing data to “learn” what makes up a benign or malignant tumor in such a way that it can classify new samples with some accuracy. Enters machine learning. Machine learning algorithms would find patterns in your dataset then further use the pattern learnt to classify new patients into benign or malignant lump carriers. In other words, they iteratively learn from data and allow computers to find hidden insights. It would learn patterns from a given data, “save” said patterns and find same in a new or unseen data. This process is known as Generalization. As such, machine learning algorithms are much shorter, easier to maintain and more accurate. Outside these, they have the ability to adapt to change rapidly especially in fluctuating environments while also helping humans learn by revealing unsuspected correlations and new trends thereby leading to a better understanding of the problem.
So far so good??? Alright, moving on…
Types of Machine Learning Algorithms.
There are so many types of machine learning algorithms that it is important to classify them into broad categories. For example, you may want to answer questions such as; what kind of algorithm would suit the type of data that I have? What do I aim to achieve? Do I want to make predictions for the future or do I want to find similarities or anomalies? These categories aim to guide you in your data science quest.
- Would they be trained with human supervision? If yes, then you have supervised learning. If no, you have unsupervised learning. If you want a little bit of both, then semi supervised learning. Do you want to train robots (agents)? you go for reinforcement learning.
- How would you like to train your algorithm? Is it best for them to learn incrementally-online or on the go-batch?
- How would the learning algorithm generalize? Would they work by comparing new data points to known data points-instance-based or rather detect patterns in training-model-based?
Let’s take a look at these categories a bit more closely.
Supervised Learning
In supervised learning, the desired outcome otherwise known as a label or class is added to the dataset that you want to feed into the algorithm. Someone might ask, if I have the desired solution already why do I need to train the dataset? The answer would be; because you would like to know about new data points without anymore programming. This is known as predictive modelling or classification algorithm depending on your perspective.
Have a look at the data below. Is our last patient of class M or B?
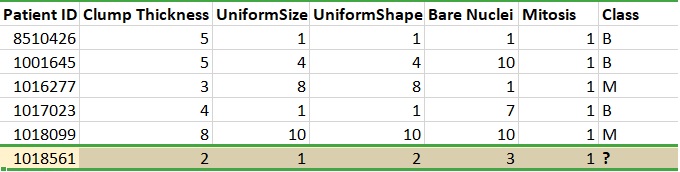
Some supervised learning algorithms that can solve these kinds of problems are: K-Nearest Neighbor, Logistic Regression, Support Vector Machines, Decision trees and Random Forests, Naive Bayes and Neural Networks. On another hand, if we have a dataset with labels as continuous values such as predicting sales, price of a house, we use Linear Regression.
Unsupervised Learning
In this type of learning, there are no labels or classifiers in the dataset. The model finds its own patterns by creating groups or clusters through similarities found between data points. Examples of these types of algorithms include; K-Means, EM Clustering using Guassian Mixture Models, DBSCAN and Hierarchical clustering. They are also great for anomaly detection. For dimensionality reduction, we use algorithms such as PCA, LLE and t-SNE. Finally, Eclat and Apriori algorithms are used for association ruling- especially used to associate customers buying patterns and products.
Semi-supervised Learning
These algorithms learn from datasets that include both labeled and unlabeled data, although most are unlabeled. Imagine you are developing a model for a bank with the intent to detect fraud. Some fraud you know about, but other instances of fraud slipped by without your knowledge. You can label the dataset with the fraud instances you’re aware of, but the rest of your data will remain unlabeled. You can use a unsupervised learning algorithm to label the data, and retrain the model using supervised learning with the newly labeled dataset. Basically, this type of learning involves using both supervised and unsupervised learning algorithms for training your model.
The best way to get the best out of this magazine is to follow the links at the end of each chapter that moves you to the next level. As far as prerequisites go, you should have some statistical background. However, if you do not, google is your friend. If you do not understand a term, you can quickly find what it means and continue your learning.
As far as machine needs go, windows users would have to download Anaconda Distribution for Python from here while MacOs users can download from here. Follow these steps to get up and running with jupyter notebook.
Without further ado, I believe it is time to get our hands dirty with a real life project starting with Linear Regression
Leave a comment